-
람다와 스트림 - 중간 연산 part 1백엔드/자바 2023. 2. 11. 07:08
람다와 스트림 - 스트림의 정의와 특징
스트림의 정의와 그 필요성 한마디로 말하면 컬렉션이나 배열을 다루기 쉽게 만든 것이다. 기존의 컬렉션 프레임웍을 보면 위와 같이 List, Set, Map의 인터페이스로 구성된 것을 알 수 있다. 이 중
sgcomputer.tistory.com
지난 번 람다와 스트림의 정의와 특징을 설명하면서 다음과 같은 그림을 보여준 적이 있다.

간단히 이야기하자면 컬렉션의 스트림 생성 및 연산에 관한 그림이었다.
오늘은 이중에서 중간 연산에 대해서 설명하고자 한다.
중간연산이란?
중간 연산은 컬렉션을 스트림화 한 후 사용자의 필요에 따라 스트림의 데이터들을 재가공하는 과정을 말한다.
중간 연산을 통해서 데이터를 자르거나 조건에 따라 거르거나 정렬하는 등의 다양한 작업을 할 수 있다.
물론 스트림의 취지에 맞게 기존에 배웠던 방식들보다 더 편하게 사용이 가능하다.
앞서 다른 글에서 공부한대로 스트림을 만들어준 다음 체이닝 형식으로 메서드를 사용하면 된다.
중간 연산과 최종 연산의 차이
이전 스트림의 정의와 특징에서 한번 이야기한 적 있지만 다시 한번 짚고자 한다.
연산은 연산인데 중간 연산과 최종 연산은 무엇이고 무슨 차이가 있을까?
다음은 임의의 정수가 들어간 리스트에서 요소들을 뽑아 중복을 거르고 짝수를 찾아 정렬 후 문자열을 더하는 코드다.

위 그림에서 빨간 줄이 처진 코드 부분이 전부 중간 연산이다.
보통 컬렉션을 다루다보면 한번에 자료 가공이 끝나지 않고 위와 같이 여러번 가공을 거치게 된다.
그 과정에서 메서드들 간에 필연적으로 자료를 주고받게 되고 자료 타입의 문제 등이 발생할 수 있다.
이러한 불편을 해결하고 편리하게 스트림을 사용하도록 중간 연산 메서드들을 따로 만든 것이다.
중간연산 메서드들은 가공한 데이터를 항상 Stream 타입으로 반환한다.
아래는 filter( )와 sorted( ) 메서드의 반환 타입을 체크 한 것이다. 위에서 말한대로 Stream임을 알 수 있다.



중간 연산 과정을 그림으로 나타내면 위와 같다.
이처럼 중간 연산 메서드들은 계산의 연계와 용이성을 위해 Stream 타입으로 자료를 주고 받는 것이다.
반면 최종 연산은 좀 다르다.

최종 연산은 데이터 재가공이 완료되어 말 그대로 더이상 연산을 하지 않는 최종 단계다.
그러므로 굳이 자료의 반환을 Stream으로 하지 않는다. 그래서 최종 연산은 반환 타입이 여러가지다.
해당 메서드에선 void지만 필요에 따라 다양한 자료 타입으로 반환이 가능하다.
정리하자면 중간 연산은 자료를 Stream으로 반환한다. 그리고 반복적으로 사용이 가능하다.
반면 최종 연산은 Stream이 아닌 다양한 타입으로 자료를 반환한다. 그리고 반복 사용이 불가하다.
중간 연산 - distinct( ): 중복 제거
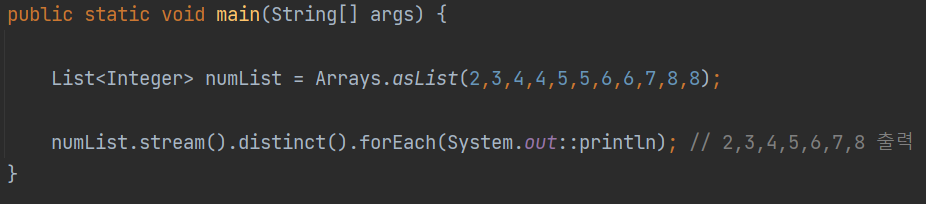
distinct()는 중복을 제거하는 중간 연산 메서드다.
위 코드에서 확인할 수 있듯이 스트림화 된 컬렉션의 데이터에서 중복을 찾아 제거하는 역할을 한다.
중간 연산 - filter( ): 자료 걸러내기

filter()는 조건에 맞지 않는 요소를 제외하는 메서드다.
이때 filter() 메서드의 매개변수로 주어지는 조건식은 함수형 인터페이스 predicate와 연동된다.
즉 조건식을 넣으면 해당 조건에 맞는 숫자는 true, 맞지 않으면 false를 반환함.
그리고 해당 요소가 false일때 스트림 데이터에서 제외한다.
중간 연산 - limit( )과 skip ( ): 데이터 잘라내기와 건너뛰기

limit()와 skip() 모두 특정 숫자 범위를 제외하는 메서드다.
limit()는 매개변수로 주어진 숫자 이후 요소는 데이터에서 제외한다.
skip()은 반대로 주어진 숫자 이전의 요소는 모두 건너뛴다.
위의 코드를 보면 limit()는 5를 매개변수로 전달해서 첫 요소부터 5번째까지 이후의 숫자는 모두 제외됐다.
반면 skip()은 5를 매개변수로 전달해서 5번째 이전의 요소인 2,4,6,8,10은 건너뛰었다.
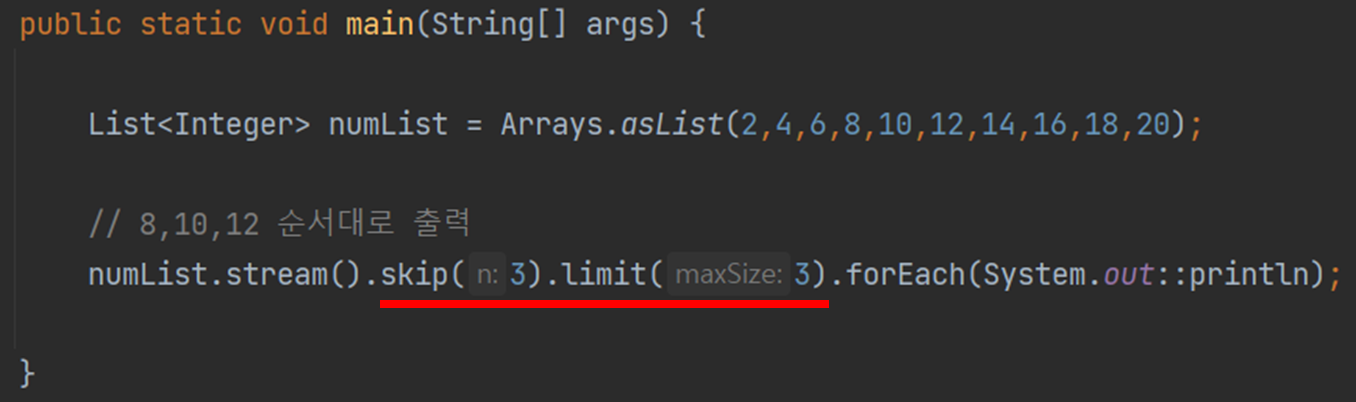
이걸 응용하면 skip과 limit를 결합해서 데이터를 가공하는 것도 가능하다.
위의 경우 skip으로 앞의 3개의 숫자를 건너뛰고, 그 뒤에 남은 숫자 중 3개까지만 남기고 그 뒤는 전부 제외하하는 코드다.
즉 2,4,6,8,10,12,14,16,18,20 => skip => 8,10,12,14,16,18,20 => limt => 8,10,12 와 같은 단계로 계산이 진행된다.
중간 연산 - sorted( ): 정렬하기

sorted()는 데이터를 정렬하는 중간 연산 메서드다.
위와 같이 중간 연산으로 sorted()를 사용하면 기본정렬에 맞춰 데이터를 정렬해준다.
하지만 여기서 중요한건 sorted()의 기본 정렬이 아니다.
실제로 데이터를 정렬할 때는 기본 정렬 뿐 아니라 역정렬이나 별도의 정렬 기준을 만들어야하는 경우도 있다.
그럴때는 sorted()의 매개변수에 정렬 기준이 되는 Comparator를 전달해줘야 한다.
혹시 Comparator에 대해 모른다면 아래를 참고하자.
컬렉션 - Comparable와 Comparator
Comparable와 Comparator는? 객체의 정렬에 필요한 메서드(정렬 기준 제공)을 정의한 인터페이스. Comparable은 특정 클래스의 기본 정렬 기준(디폴트)를 구현하기 위해 사용된다. 반면 Comparator는 기본 정
sgcomputer.tistory.com
우선 기본적으로 미리 만들어져있는 Comparator에 대해 알아보자.

미리 만들어진 Comparator의 종류는 많지만 우선 위의 네 가지를 가장 많이 쓴다고 보면 될 것이다.
Comparator.naturalOrder(): 기본 정렬. 이 경우엔 리스트의 요소들이 String이므로 String 기본 정렬 법칙을 따른다.
Comparator.reverseOrder(): 역정렬. 이 경우엔 String의 기본 정렬의 반대로 정렬한다.
String.CASE_INSENSITIVE_ORDER: String클래스가 제공하는 Comparator. 대소문자 구분없이 정렬.
String.CASE_INSENSITIVE_ORDER.reversed(): Comparator에 reversed() 메서드 사용. 대소문자 구분없이 역정렬.
이 정도면 아주 기본적인 자료타입을 가진 리스트들은 정렬이 가능하다.
하지만 별도의 정렬을 기준 만들어야 하는 경우엔 어떻게 할까?
중간 연산 - sorted( ): 정렬하기 + 새로운 정렬 기준 만들기
class WorldCup implements Comparable{ String name; String continent; int round; WorldCup(){}; WorldCup(String name, String continent, int round) { this.name = name; this.continent = continent; this.round = round; }; String getName(){ return this.name; } String getContinent(){ return this.continent; } int getRound(){ return this.round; } public String toString(){ return this.continent+" : "+this.name+" : "+this.round; }; @Override public int compareTo(Object o) { WorldCup country = (WorldCup) o; return this.name.compareTo(country.name); } }예를 들어 위와 같이 월드컵 관련 정보를 가진 객체를 만들 수 있는 클래스가 있다고 가정해보자.

이제 객체를 만들고나서 리스트에 넣은 뒤 스트림을 만들어 정렬 후 출력해보자.

국가가 이름 순으로 정렬된 출력 결과를 볼 수 있다.

이것은 클래스를 작성할 때 기본 정렬을 만드는 compareTo()의 코드를 이름 순으로 정렬하도록 작성했기 때문이다.
그렇다면 해당 객체들을 정렬할 때 다른 기준으로 정렬하고 싶다면 어떻게 해야할까?
우리가 기존에 배운 방법대로라면 Comparator 인터페이스를 구현한 클래스를 별도로 작성해야한다.
그것도 아니라면 매개변수에 직접 Comparator 인터페이스를 구현한 익명 클래스를 작성해야한다.
물론 이것이 기본적인 방법이지만 다소 번거로운 것이 사실이다.
스트림에서 데이터를 정렬할 때는 더 간단한 방법이 있다.
바로 Comparator 인터페이스가 가진 static 메서드인 comparing()을 쓰는 것이다.
comparing()은 매개변수로 비교 기준이 될 멤버들의 정보만 넘겨주면 알아서 정렬 기준을 만들어준다.

예를 들어 월드컵에 진출한 나라를 대륙별로 분류하고 싶다면 위와 같이 코드를 짜면 된다.
comparing() 메서드의 매개변수에 getContinent()로 대륙별 정보를 전달한다.
그러면 다음과 같은 결과를 얻을 수 있다.

getter를 이용해 멤버 변수들을 제공한 것만으로도 대륙별로 정렬이 된 것을 볼 수 있다.
이는 별도의 Comparator를 구현한 클래스를 만들거나 익명 클래스를 만들 필요가 없어서 굉장히 편리하다..
하지만 여기서 대륙별로 정렬하고 추가적으로 국가 이름 별로 정렬하고 싶다면 어떻게 해야할까?
그때는 compring() 메서드에 이어 thenComparing() 메서드를 이용하면 된다.

thenComparing() 메서드는 comparing()과 마찬가지로 Comparator의 static 메서드로 추가 기준을 줄 때 쓴다.
사용법은 위 그림과 같이 comparing() 코드를 작성한 뒤 체이닝으로 뒤에 바로 써주면 된다.
위 코드는 대륙별로 우선 정렬 후 그 안에서 이름 별로 정렬하는 코드로 결과는 다음과 같다.

코드를 작성한 대로 대륙별 / 이름별로 정렬된 내용을 확인할 수 있다.
이와 같이 Comparator 인터페이스의 comparing() 메서드를 잘 사용하면 편리한 정렬이 가능하다.
'백엔드 > 자바' 카테고리의 다른 글
람다와 스트림 - Optional<T> (0) 2023.04.17 람다와 스트림 - 중간 연산 part 2 (0) 2023.02.13 람다와 스트림 - 스트림 만들기 (0) 2021.11.09 람다와 스트림 - 스트림의 정의와 특징 (0) 2021.09.15 람다와 스트림 - 메소드 참조(method reference) (0) 2021.09.14