-
컬렉션 Set - TreeSet백엔드/자바 2020. 8. 16. 06:08
TreeSet이란?
Set의 인터페이스를 구현한 컬렉션 클래스다.
이진 탐색 트리(binary search tree)라는 자료구조 형태로 데이터를 저장한다.
그리고 당연히 Set 인터페이스를 구현했기에 중복을 허용하지 않는다.
또한 이진검색트리 구조에 맞게 정렬된 상태로 데이터가 저장되므로 저장 순서를 유지하지도 않는다.
즉 내부적으로 데이터 정렬은 가능하지만, 사용자의 데이터 입력 순으로 저장 순서가 유지되진 않는다.
이진 트리(binary tree)란?
이진 트리란 루트에서 시작하여 한 개 부모 노드에 최대 2개의 자식 노드를 붙일 수 있게 설계된
데이터를 저장할 수 있는 자료 구조를 말한다.
그림으로 보는게 더 이해하기 쉽다.

루트를 기준으로 여러 개의 요소(노드, node)가 서로 연결된 구조다.
1개의 부모 노드는 최대 2개의 자식 노드( 0~2개 )를 가질 수 있다.
노드가 많을수록 루트를 기준으로 아래로 뻗어 나가는 구조를 가지게 되며,
자식이 부모가 되어 자식을 갖는 식으로 계속 확장된다.
이때 각각 노드를 트리노드라고도 부른다.
이때 각 트리노드는 저장할 객체, 왼쪽 자식 노드의 정보, 오른쪽 자식 노드의 정보 총 3개의 정보를 갖는다.
이진 트리는 다양한 종류를 갖는데, treeSet은 그 중 이진 탐색 트리 형태로 데이터를 저장한다.
이진 탐색 트리란(binary search tree)란?
이진 탐색 트리란 이진 트리의 한 종류로서
부모 노드를 기준으로 왼쪽 자식 노드는 부모 노드보다 작은 값,
오른쪽 자식 노드는 부모 노드보다 큰 값을 갖는 트리 형태다.
좀 더 편하게 이해하려면 아래 그림을 보도록 하자.

기본적으로 이진 트리의 형태를 띄고 있으며 위와 같은 형태로 자료를 저장할 경우 이진탐색트리라 한다.
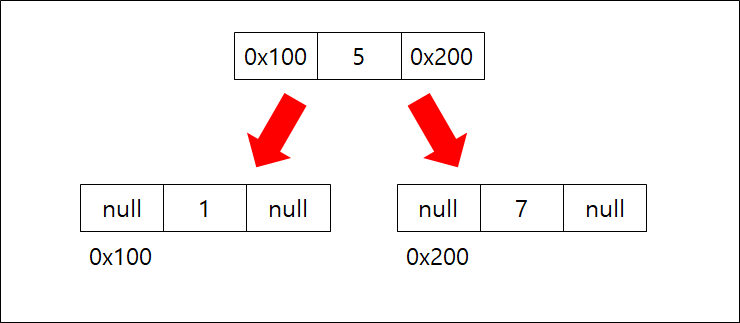
만약 메모리 값을 기준으로 나타낸다면 위와 같이 나타낼 수 있다.
TreeSet 저장 방식과 그 단점
treeSet을 사용하기전 treesSet이 구현하는 이진탐색트리의 데이터 저장 방식에 대해 알아둘 필요가 있다.
아무래도 이진탐색트리에 대한 이해가 있어야 treeSet에 대한 세세한 이해가 가능하기 때문이다.
예를 들어 7,4,9,1,5 순서로 데이터를 저장한다고 가정해보자.
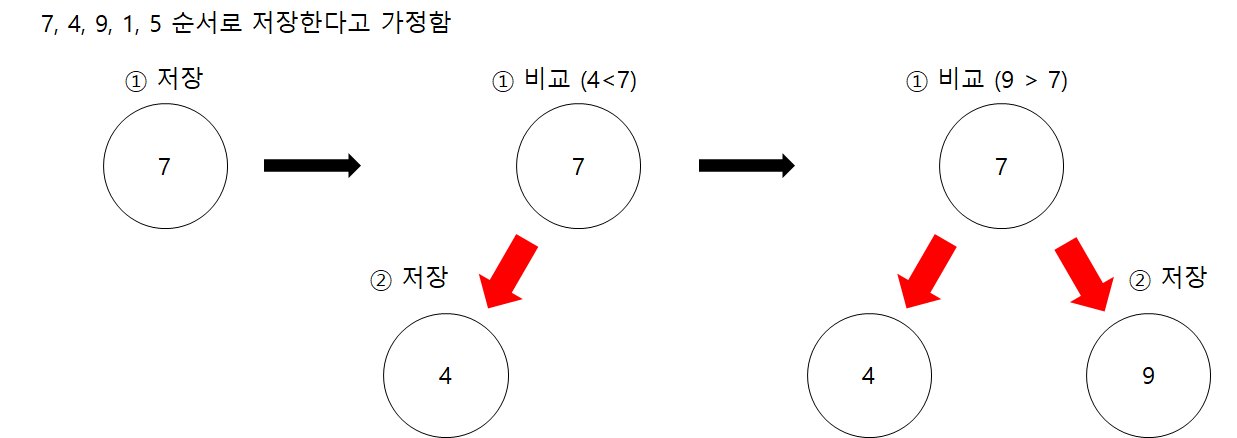

그림을 보면 알겠지만 이진 탐색 트리는 처음을 제외하고는 매번 저장할 때마다 비교 과정이 일어난다.
지금은 저장하는 숫자가 5개라 얼마 안되지만, 많은 데이터를 다룰 수록 비교 횟수는 더 늘어난다.
이러한 이진 탐색 트리의 특성은 데이터의 추가, 삭제를 느리게 만든다.
그리고 당연히 이러한 저장 방식을 채용한 treeSet은 hashSet에 비해 데이터 추가, 삭제가 느리다.
TreeSet의 검색 방식과 장점
이전에 올린 hashSet포스트에서, treeSet은 hashSet에 비해 범위 검색, 정렬에 장점이 있다고 했었다.
이는 이전 단락에서 이진 탐색 트리의 저장 방식을 통해 treeSet의 단점을 알아본 것처럼
이번 단락에선 이진 탐색 트리의 데이터 검색 방식을 통해 treeSet의 장점을 알아볼 것이다.
예를 들어 10, 35, 45, 50, 65, 80, 95, 100의 숫자가 들어있는 정렬된 리스트가 있다고 가정해보자.
아마도 그림으로 나타내면 아래와 같을 것이다.

이제 이 리스트에서 55보다 작은 숫자들을 찾아본다고 가정해보자.

이 경우 총 5번의 조회가 일어난다.
각 요소 별 숫자를 조회하고, 최종적으로는 다음 요소가 55보다 클 경우까지 살펴봐야 하기 때문이다.
이제 10, 35, 45, 50, 65, 80, 95, 100을 이진 탐색 트리에 넣고 조회해보자.

그림을 보면 알겠지만 이진 탐색 트리는 단 세번의 조회로 55보다 작은 숫자를 걸러냈다.
처음 숫자를 저장할 때부터 대소를 비교해 저장하므로 위와 같은 식으로 범위 검색에 굉장히 유리하다.
그리고 당연히 treeSet은 이러한 검색 방식을 이용하므로 범위 검색에 장점을 가진다.
또한 treeSet은 이러한 검색 방식을 메서드로 사용할 수 있게 만들어져 더욱 편하게 범위 검색이 가능하다.
TreeSet 이용해보기
이제 직접 treeSet을 이용해보자.
위에서 말한대로 treeSet은 검색과 관련된 다양한 메서드를 제공하는데 이것들을 확인해볼 수 있다.

우선 10, 20, 30, 40, 50, 60, 70, 80의 숫자를 차례대로 add()메서드로 TreeSet에 넣어보자.
사실 저 순서대로 treeSet에 저장되면 굉장히 극단적인 트리가 나오는데,
실제로는 자바에서 보정해서 정렬한 상태로 트리를 구성하기 때문에 걱정할 필요는 없다.
대략 트리로 나타낸다면 아래와 같을 것이다.

우선 범위 특정 객체를 기준으로 그보다 작은 범위, 큰 범위를 검색하는 메서드를 사용해보자.
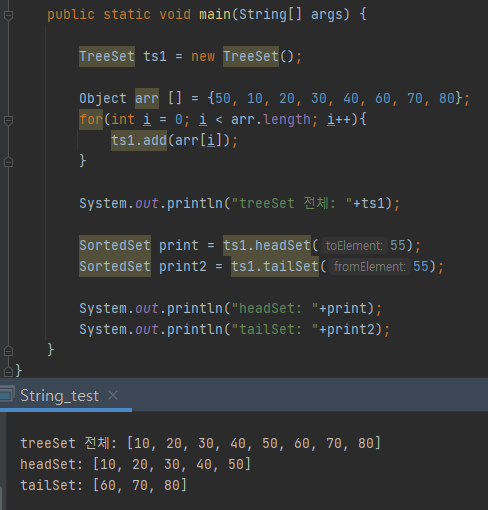
위 코드처럼 headSet()과 tailSet() 메서드로 특정 객체를 기준으로 큰 객체, 작은 객체의 범위를 알 수 있다.
그림으로 나타내면 대략 이렇다.

특정한 객체를 기준으로 그보다 작은 범위 검색은 headSet(), 큰 범위는 tailSet()을 써주면 된다.
데이터들이 트리 형태로 저장되어있기 때문에 이처럼 쉽게 범위 검색이 가능하다.
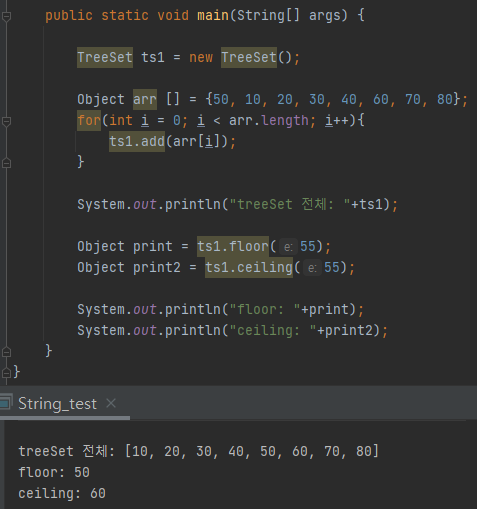

위 코드처럼 floor()를 쓰면 기준보다 작은 객체들 중 가장 가까운 객체를 반환한다.
반대로 ceiling()을 쓰면 기준보다 큰 객체들 중 가까운 객체를 반환한다.
그래서 55를 기준으로 했을 때 floor는 50, ceiling은 60이 나온 것을 확인할 수 있다.
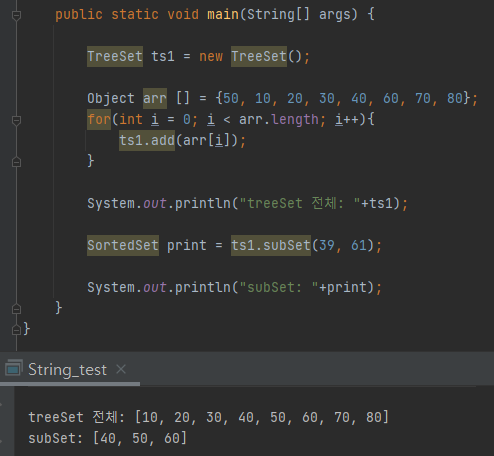

마지막으로 subSet() 메서드를 사용할 경우 왼쪽과 오른쪽 숫자 사이의 범위를 검색할 수 있다.
코드에서 숫자 39~61 사이의 범위를 검색해달라고 요청했기 때문에 40, 50, 60을 반환한걸 볼 수 있다.
'백엔드 > 자바' 카테고리의 다른 글
컬렉션 Map - TreeMap (0) 2020.08.17 컬렉션 Map - HashMap (0) 2020.08.17 컬렉션 Set - HashSet (0) 2020.08.16 컬렉션 List - Stack & Queue (0) 2020.08.16 컬렉션 List - LinkedList (0) 2020.08.16