-
람다와 스트림 - collect() part 2백엔드/자바 2023. 4. 19. 09:08
람다와 스트림 - collect() part1
collect()란? collect()란 스트림의 최종 연산 중 하나의 과정이다. 사실 다른 최종 연산과 같이 다뤄야하나 비중이 크다보니 별도로 다룰 것이다. collect()는 간단히 말하면 다양한 콜렉션 자료들을 쉽
sgcomputer.tistory.com
지난 번에 이어서 이번에는 collect()의 여러 기능 중 하나인 분할에 대해서 공부해보자.
collect()는 스트림으로 만들어진 데이터를 쉽게 다루기 위한 메서드라고 이전 파트에서 배웠다.
하지만 이전 파트에서는 단일 스트림을 다루는 방법에 대해서만 배웠다.
이번에는 collect()를 이용해 스트림을 분할하여 나눈 데이터를 다루는 방법을 배울 것이다.
partitioningBy()와 groupingBy()
스트림을 분할하기 위해서는 크게 두 가지 방법이 있다.
바로 partitioningBy()와 groupingBy()다.
둘의 차이를 설명하자면 partitioningBy()는 스트림을 2분할, groupingBy()는 다중 분할이 가능하다.
예를 들어 한 반의 학생들을 남, 녀 둘로 나눌때는 partitioningBy()를 쓰는 것이 유리하다.
반면 한 반의 학생들을 점수별로 여러 그룹으로 나눌 때는 groupingBy()를 써야한다.
물론 groupingBy()로도 2분할을 할 순 있지만 그보단 partitioningBy()를 쓰는게 효율적이다.
partitioningBy(): 스트림의 2분할
이전 단락에서 이야기했듯 스트림을 둘로 나눌 때는 partitioningBy()를 쓰게 된다.
분할을 하는 기능은 같지만 partitioningBy()의 경우 결과 값을 반환할 때 key값으로 true, false로 반환한다.
그렇기 때문에 groupingBy()보다는 2분할을 하는데는 partitioningBy()이 적절하다.
사실 이 부분의 경우 설명보다 코드를 보는게 더 이해하기 쉽다.
partitioningBy() : 2분할 하기

우선은 위 코드를 따라하면 간단하게 2분할이 가능하다.
학생 정보를 가진 리스트의 스트림을 생성한 뒤 collect() 메서드 안에서 partitioningBy()를 사용하면 된다.
그리고나서 partitioningBy()안에는 람다식을 통해 메서드 기준을 전달하면 데이터 스트림의 분할은 끝이다.
이때 partitioningBy()의 결과는 Map의 형태 즉 key와 value의 나눠 반환된다.
key의 경우 true, false로 나뉘고 value의 경우는 학생 정보가 담긴 객체를 담은 리스트 형태로 반환된다.
앞서 이야기했듯 partitioningBy()의 경우 true, false를 key로 반환하므로 2분할에 적합하다.
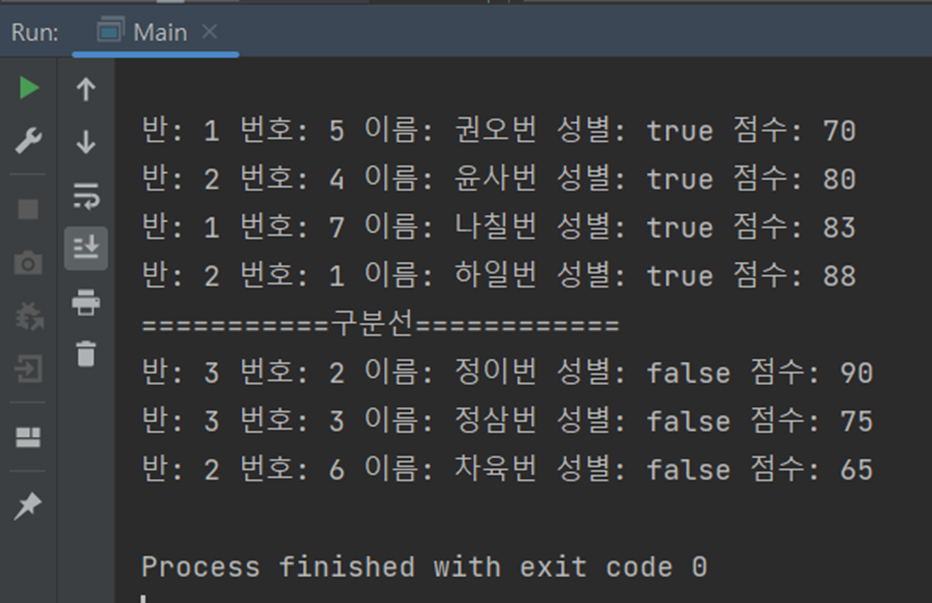
그 뒤에 key값을 기준으로 학생 정보를 출력한 결과는 위와 같다.
true와 false를 기준으로 데이터가 분할된 것을 쉽게 확인할 수 있다.
partitioningBy() + coungting() : 2분할 하기 + 숫자 세기
이번에는 단순 분할 후 추가적으로 다양한 통계 기능을 이용하는 걸 실습해보자.
이전 단락에서 말했듯 collectors 클래스가 제공하는 다양한 통계 기능이 있다.
counting(), summingInt(), maxBy(), minBy() 등이 그것이다.
물론 분할을 하지 않은 스트림에서 사용 가능한 메서드도 있다.
하지만 collectors가 제공하는 메서드는 분할된 스트림에서도 사용가능한 것이 특징이다.
우선 이번 단락에서는 분할된 스트림의 갯수를 세는 counting()에 대해 알아보자.
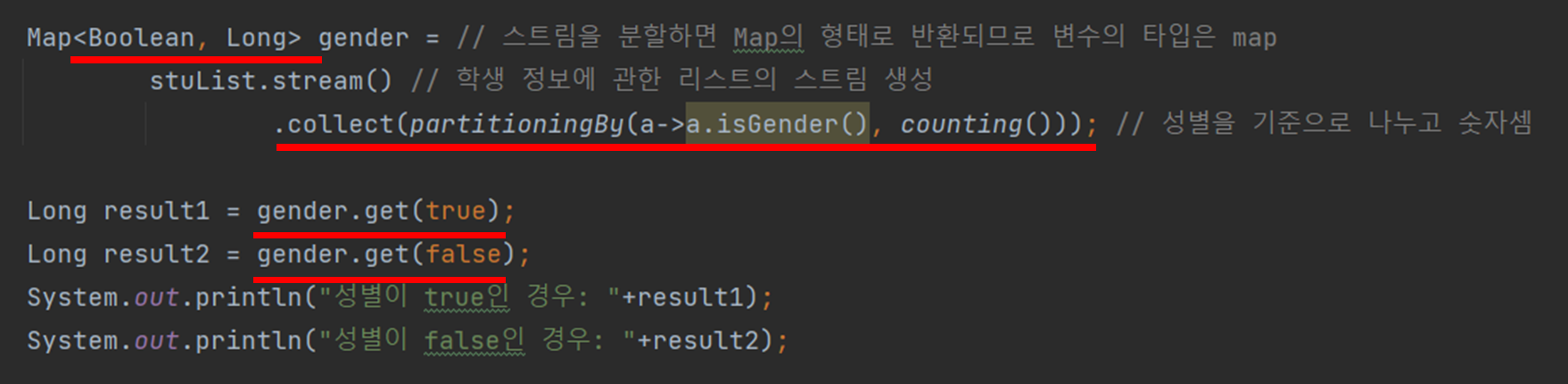
counting() 메서드를 사용하는 것은 아주 간단한다.
이전 단락에서 partitioningBy()을 사용한 것에 추가적으로 counting() 사용을 명시해주면 끝이다.
위 코드의 경우 성별로 나눈 뒤 그 성별 숫자를 세서 반환하는 내용이다.
이때 주의 할점은 partitioningBy()이 반환하는 key값은 true, false로 반환된다.
하지만 value는 숫자로 반환된다는 점이다.
그래서 Map의 지네릭스는 <Boolean, List<Students>>에서 <Boolean, Long>으로 바꿔야 한다.

결과는 위와 같다. true를 성별로 가진 학생은 4명이고 false를 성별로 가진 학생은 3인걸 알 수 있다.
partitioningBy() + maxBy() : 2분할 하기 + 최고점자 선택
이전 단락에서 성별로 2분할 하고나서 그 분할된 학생들의 수를 세는 코드에 대해 공부해봤다.
이번에는 성별로 분할된 학생들 중 최고 점수를 가진 학생을 찾아보는 maxBy()에 대해 공부해보자.

위 코드를 딱 봤을 때 counting()과 달리 조금 복잡하다는 것을 느낄 수 있을 것이다.
maxBy()의 경우 별도의 비교 기준이 필요하므로 그걸 제공하는 과정에서 다소 코드가 길어지기 때문이다.
하지만 이 또한 분리해서 보면 크게 어려울 것도 없다.

위 코드에서 collect()의 괄호를 층위별로 색깔을 다르게 해서 나타낸 그림이다.
여기서 collect()안에서 partitioningBy()를 사용하는 것은 이전 단락들의 코드와 다를 바가 없다.
그 다음 partitioningBy() 안에서 isGender() 메서드 다음 maxBy()를 써준다.
이제 maxBy()를 쓸 때는 어떤 걸 기준으로 최고 숫자를 뽑을 지 비교 기준을 전달해야한다.
이때 Comparator 인터페이스가 제공하는 comparing() 메서드를 사용해야 한다.
그리고 나서 comparing() 메서드 안에 비교기준으로 사용할 데이터를 불러오면 된다.
위 코드의 경우 최고점을 받은 사람을 뽑는 것이므로 getScore()를 통해 각 학생들의 점수를 불러온다.
이때 한 가지 주의할 점은 maxBy()의 경우 반환 타입이 Optional이므로 지네릭스 수정이 꼭 필요하다.

위 코드의 결과는 그림과 같다.
각 성별(true/false)에서 가장 높은 점수를 받은 사람 둘을 걸러낸 것을 볼 수 있다.
partitioningBy() + partitioningBy() : 분할의 재분할
지금까지 partitioningBy()은 2분할이 가능하다고 공부했다.
하지만 실제로 partitioningBy()을 여러번 사용하면 다중 분할이 가능하다.
이번에는 partitioningBy()을 두번 사용해서 2+2 4중 분할하는 방법에 대해 알아보도록 하자.
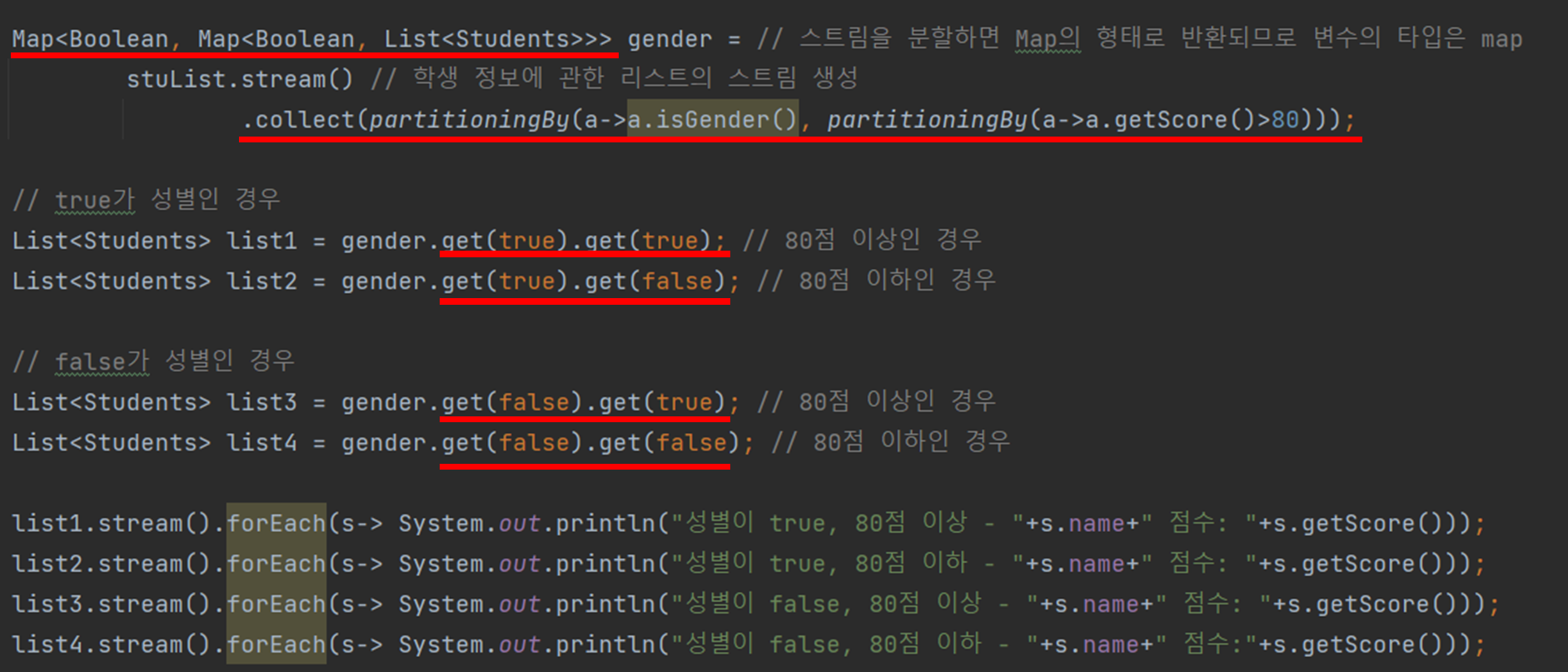
위 코드는 학생들을 성별로 나누고 80점 이상과 이하인 경우로 나눠 스트림을 총 4개로 분할하는 코드다.
대충 보면 알겠지만 Map에서 value 안에 Map을 한번 더 써준 형태라고 생각하면 된다.

위의 코드의 구조를 그림으로 나타내면 위와 같다.
즉 Map안의 value에 Map을 하나 더 넣어서 4분할로 만들어준 것과 같다.
변수의 지네릭스를 보면 위와 같은 구조임을 확인할 수 있다.
partitioningBy()안에 기존과 마찬가지로 isgender() 메서드를 사용한 뒤 partitioningBy()를 한 번 더 쓰면 된다.
이때 안쪽의 partitioningBy()는 학생들의 점수를 받아와서 80점보다 높으면 true, 낮으면 false로 반환한다.

그리고 결과는 위와 같다.
성별로 점수별로 분류되서 출력된 것을 확인할 수 있다.
물론 다중 분할은 groupingBy()를 사용하는 것이 맞지만, 이렇게 다른 식으로 다중 분할이 가능하다.
groupingBy(): 스트림의 다중 분할
이전 단락에서는 partitioningBy()를 통해 스트림을 분할하는 방법을 배웠다.
partitioningBy()는 2분할을 기본으로 한다.
물론 다중 분할은 가능하지만, partitioningBy()를 중복으로 사용해서 분할의 분할을 하는 식이다.
그와 달리 groupingBy()은 처음부터 다중 분할이 가능하다.
이번에도 코드를 통해서 알아보자.
groupingBy() : 다중 분할하기
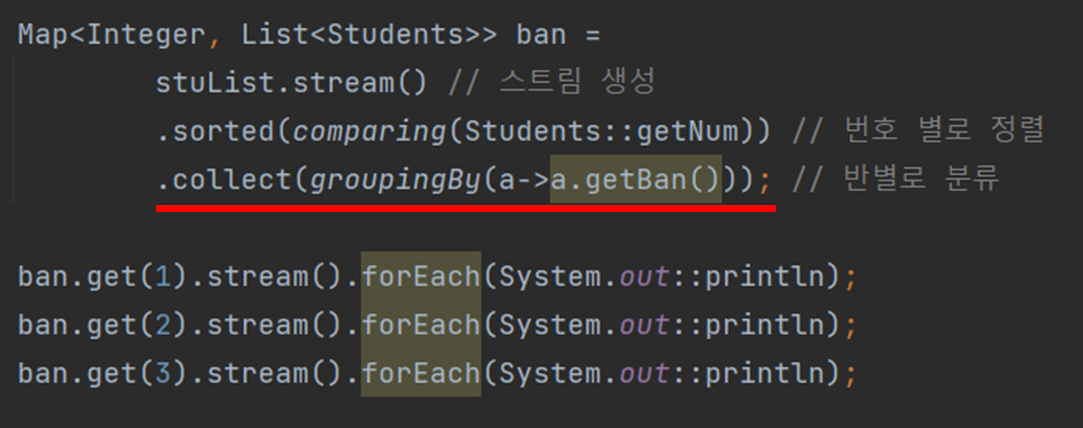
이전 단락에서 배운 partitioningBy()를 잘 따라왔다면 groupingBy()도 그리 어렵지 않다.
위 그림은 groupingBy()를 이용해서 반별로 분류를 한 코드를 나타낸 것이다.
스트림을 생성하고 collect()를 사용한 뒤 그 안에서 groupingBy()를 사용하면 분할은 끝난다.
이때 groupingBy()에서 어떤 데이터를 불러오느냐에 따라 분할 기준이 달라진다고 보면 된다.
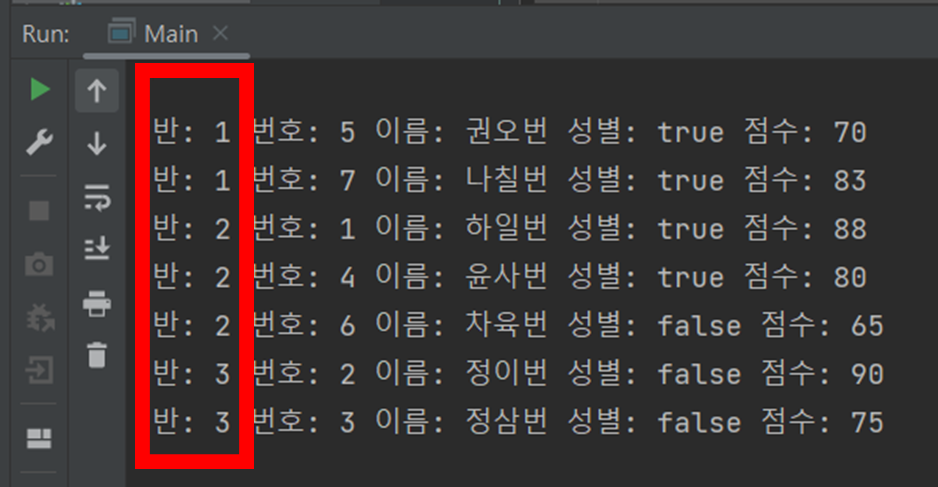
해당 코드의 결과는 위 그림과 같다.
1,2,3반으로 나뉜 것을 확인할 수 있다.
groupingBy() + counting() : 다중분할 + 숫자 세기

이전 partitioningBy() 파트에서 배운 것처럼 groupingBy()에서도 counting() 사용이 가능하다.
사용 방법은 partitioningBy()와 마찬가지로 어렵지 않다.
groupingBy()안에 그냥 원하는 분류 데이터를 불러온 뒤 counting()를 사용해주면 된다.
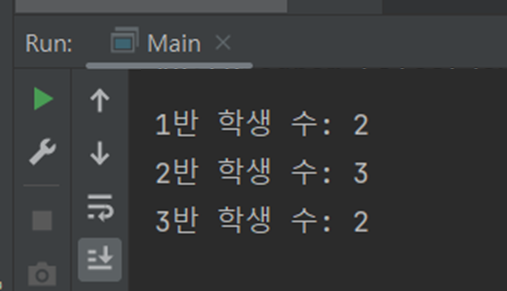
코드의 결과는 위와 같다.
groupingBy() + maxBy() : 다중 분할 및 최고 숫자 찾기
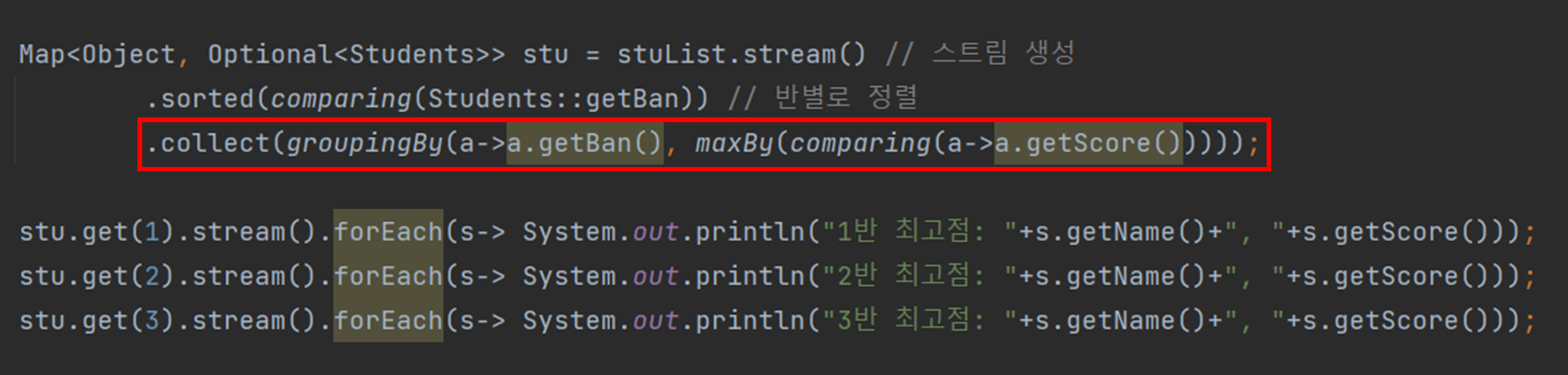
groupingBy()를 maxBy()를 사용하는 것도 partitioningBy()에서 maxBy()를 써준 것과 사용법은 동일하다.
collect() 안에서 groupingBy()를 사용하고 그 뒤에 maxBy()를 쓰면 된다.
이때 maxBy()안에서는 Comparator 인터페이스가 제공하는 comparing()메서드를 사용한다.
그리고 comparing()안에서 학생의 점수 데이터를 불러오면 각 반별로 최고 점수가 누군지 알 수 있다.

결과는 위와 같다.
maxBy()를 사용하는건 groupingBy()나 partitioningBy()이나 동일하기에 크게 어렵지 않을 것이다.
groupingBy() : 그룹 내 조건을 주어 분할하기
이번에는 점수 별로 학생 그룹을 3분할 하는 방법을 알아보자.
사실 partitioningBy()을 이용할 때는 조건부 분할은 어렵지 않았다.
하지만 groupingBy()는 분할 그룹 수가 많아지므로 코드가 조금 복잡해진다.

코드를 보면 groupingBy() 안에 if조건문을 넣다보니 코드가 복잡해보일 뿐, 내용 자체는 어렵지 않다.
이전에 점수 데이터를 불러와 분류한 것과 달리 이번에는 if문을 넣어 점수 범위 별로 분류한 것일 뿐이다.
80점 이상을 받으면 상위, 70점 이상은 중간, 그 이하는 하위로 분류하는 코드인데
분류할 때 반환해주는 Students클래스를 만들 때 미리 작성해둔 열거형 상수를 사용한 것이다.
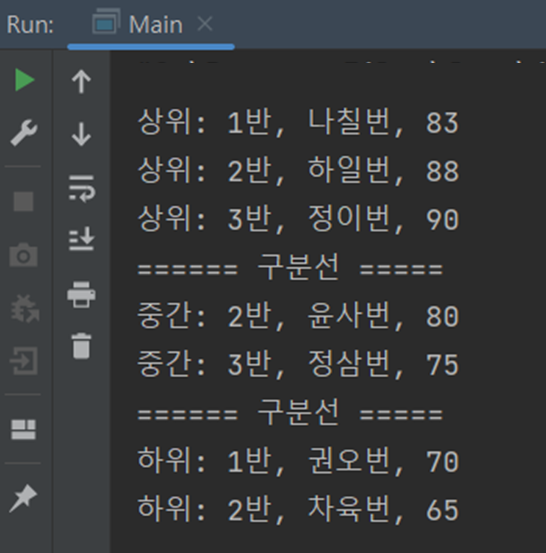
위의 코드를 실행한 결과는 위 그림과 같다.
내용에서 볼 수 있듯이 조건에 따라 점수별로 학생들을 3분할 한 것을 확인할 수 있다.
groupingBy() + partitioningBy() : 다중분할 내 이중 분할
이번에는 학생을 반별로 나눈 뒤 그 안에서 80점을 기준으로 학생을 재분류하는 방법을 알아보자.
이 경우에는 아주 간단하게 groupingBy() + partitioningBy() 형태로 코드를 짜주면 된다.
groupingBy()는 partitioningBy()처럼 특정 기준을 가지고 분할하려면 코드가 복잡해진다.
간단하게 분할하고자하면 이 방법을 사용하는게 나쁘지 않다.

코드가 복잡해 보일지 몰라도 이전에 배운 partitioningBy()를 groupingBy()와 함께 collect()안에 써준 것 뿐이다.
우선 groupingBy()를 통해서 학생을 반별로 분할하고 partitioningBy()으로 점수별로 분할한 것이다.

위 코드의 구조를 그림으로 나타내면 위와 같다.
우선 반별로 나누고 그 다음 해당 value안에서 true, value 둘로 나눠주는 것이다.
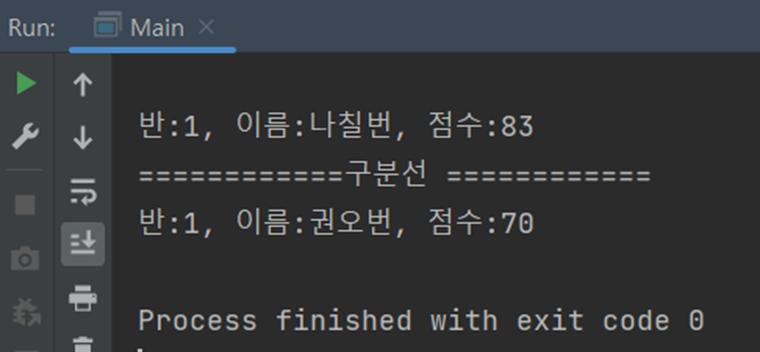
코드의 실행 결과는 위의 그림과 같다.
예상한대로 반별로 분할하고 점수 별로 분할한 결과물을 확인할 수 있다.
'백엔드 > 자바' 카테고리의 다른 글
람다와 스트림 - collect() part1 (0) 2023.04.17 람다와 스트림 - 최종 연산 (0) 2023.04.17 람다와 스트림 - Optional<T> (0) 2023.04.17 람다와 스트림 - 중간 연산 part 2 (0) 2023.02.13 람다와 스트림 - 중간 연산 part 1 (0) 2023.02.11